�����������AlphaGo
����������Դ��֪�� ���ߣ����Ṧ����˴�
������2017��10��19��DeepMind�����������³ɹ�AlphaGo zero�� ���㷨������Ҫѧϰ�������ֵ��·�����ֱ�Ӳ����Զ��Ľ���ѵ����AlphaGo zero��ѵ��Ч�������ձ��������֮ǰ�����˷dz���Ľ�������
�����Ҷ��������ģ��Ա�ǰһ���汾�����ģ���AlphaGo Fan�汾����ֱ�۸������£�
�����ɰ�AlphaGo��
AlphaGo Zero�� ����Ҷ�Χ��һ����֪��������AlphaGo�����ģ����ܻ����������ʣ� ������������ͼ�ֵ���磬�ṹ���ܺܽӽ�����Ϊʲô���ϲ���һ���أ�
����ΪʲôҪ��ר�ҵ�������Ϊ��ʼѵ����������һ�Ű�ֽ��ʼѵ�����Ǹ������ձ��ԣ�
��������������ʲô����ֻ�ü�ֵ�����������Ǹ���Ч����
����ΪʲôҪ����Χ��֪ʶ��AlphaGo��ǿ��ѧϰ�����ѵ�ѧ������Щ֪ʶ��
�����ɰ��AlphaGo����Ȼ��С�ɣ�������ۼ�����������һֻ������Ů�ѣ����о�ɫ���գ�ȴ���Ż�е�֡���������ȸ���������Χ���˹����ܣ�Ӧ���Ǽ�ࡢ���š���Ȼ��ɣ�������լ�ǵ�������ԫ����һ������������
�������°��AlphaGo��������������������Gakki����
���������˵��AlphaGo Zero����ڳ���AlphaGo�������¼���Ľ���
����1������������ͼ�ֵ����ϲ������һ������ͬʱ�������p�ͼ�ֵv�������硣
����1.1������������Ľṹ���²��ԡ���ֵ�������������ƽ����48�����ٵ���17�������У��漰Χ��֪ʶ����������������liberty�������ӣ�ladder������ɾȥ��
����2���²��ԡ���ֵ����ֻ��ͨ��ǿ��ѧϰ��ѵ��������ලѧϰ�������������������������Ϊ��ʼѵ��������ֻ�������������Ϊ��ʼѵ��������
����3���Ż������ؿ�������������Ҫ��ʡȥ�˿������ӣ�rollout policy������Լ����ʵս����ɱ���
����3.1�� �������Ӳ���Ҳ��Ҫ�������������֪��Χ��֪ʶ��������ε������ۣ�Nakade�� �����ֱ�������ġ�����������͵�Ψһ�з�����ʡȥ�������ӣ�Ҳ��ʡȥ��������Щ֪ʶ���鷳��
����4���ľ�������Ϊ�в����磬���ѵ��Ч�ʡ�
�������µģ���һ�����㿪ʼѵ���������磬�Լ��ü������ټ�MCTS�㷨�����AlphaGo Zero��
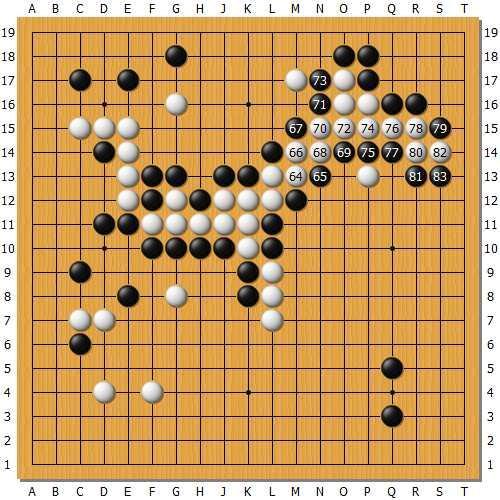
����֪�����ѡ���Щ�Ľ�ò�Ʋ����뵽������ΪAlphaGo Zero���������о��������е�Ů������AlphaGo����Ů������Ϊ�о��߲��룬������ʱ���������ٸ����ӣ�AlphaGo Fan�汾�У��������������48������ƽ�湹�ɡ���������ƽ��ֱ��ʾ��ijһ�����Ƿ��dzɹ������ӣ���ijһ�����Ƿ��dzɹ��������ӡ�
�����������ӵĻ���ͼ����1���ܣ���2��4���·ֱ������г��壬ʹ��ʼ��ֻ��һ������һֱ�����̾�ͷ����������·���ӡ�������ȫʤ��
���������·���жԷ���С����Ӧ��������ͼ���Ͻǵĺ��塣��ô���Ӿͻ�ʧ�ܣ����Ұ������̽��䡣 ����������Χ��Ļ���֪ʶ����ѧ����ǰ�����ڿξͻ�ѧ������ʵս�����ӿ��Էdz����ӣ���������ְҵ���֡�
��������ͼ����ְҵ���ף����ƽ�ʤ��������ע�⣬��������һ�����Ѿ��������ˡ�������������������ȫ�̽��䡣
����Ӳ�ܵĺ����ͼ����ȫ����û ��������Ҳ�ܸ��������硣�Ҹղ���ij�����Χ�������������Joona Kiiski���ѵĹ۵㣬�ʹ�ҷ���һ�£�
- The learning was based on self-play�� Understanding ladders is perhaps not so important if your opponent doesn��t understand them either������ Every time a decisive ladder appears on the board�� the result is practically a coin toss��- And as others have pointed out�� unlike almost all other go features�� ladders are not at all a local feature�� The features need to build up through a huge number of convolution layers�� before it works�� And it��s difficult to build this understanding incrementally ��unlike e.g�� life & death where you can start with simple cases and then move to more difficult cases���� so we lack bias to direct the learning to the right direction��
�����������£�
�;���Χ�������������������ӡ���ʽ�ȣ���ͬ��������ȫ���Ǿֲ�����������ȫ�������������ζ�ţ�������������ȷ��������֮ǰ�����ӵ�������Ҫͨ�����������������������������������ѵ������DZ�ڵ��鷳��
������Ҫ�����ǣ���������һ������ʧ��ʤ����ֻ�ֱ�ӱ�ɴ�ܡ�
�����ݴ˿����Ʋ⣬���ӵ���Щ�鷳���ԣ�ʹ�ó���AlphaGo���ò���������Ϊ���������������֮һ������һ������Zen����ʹ�ͳ���AlphaGo�������ƵĴ�����ʵս��������Ȼ��ż��������������������Ϯ�˺ö��̡���
����AlphaGo Zero�������磬��ʡȥ���������������롣ϸϸƷζѵ�����̣����Ծ���������ֱ��ѵ���ģ���ԣ����ڲ�ѧ�����ӡ�
��������Ծ�˫������AlphaGo-��AlphaGo�����������ӣ���ô������Ҳ�����̫��ɡ�ÿ�����ӵĽ���ͺ���ͶӲ��һ��������ܵ�ʤ��������������㣨����
���������ǿ����ŶӺ��ˣ����п����Ƿ��������Ժ�ųɹ�����֮���������ϣ�AlphaGo Zero���չ��ء�
����ͬ�����ֲ���ԡ���ֵ���磬�Լ����ÿ������ӣ��Ǿɰ�AlphaGo����ʱ��Э�������°����ڵ��Խ����
����DeepMind������ĸ��˾�ȸ���ռ�Ŀ�겻���ƽ�Χ�壬�������ͨ���˹����ܡ�ͨ�����ܲ���Ҫ����רҵ֪ʶ��AlphaGo Zero����Χ��֪ʶ�����ǰ���´ﵽ��˸߶ȣ�����˵��ͨ�������ֽ���һ����
�������������AlphaGo������ģ����������ġ�
����˵�塣
�������������������룬���㣨Zero��˵�������ʼѵ������������ȥ������ս�����������������εġ������桱������������������
�������ֲ����ǣ�Zero��������ѵ���ʹﵽAlphaGo Lee��ˮƽ ����ȥ��սʤ�����h�İ汾��ELO ~3750���ԱȽ��տ½�ELO ~3660��������Լ��90%+��ʱ�䡣����ͼ��
������ʮ��֮��Zero������Խ�˽��ð汾Master����Masterʵ��90%ʤ�ʡ�Master��Zero����Ҫ�����ǣ�Master�������������룬�����ලѧϰ��SL������ǿ��ѧϰ��RL����
��������������ѧ����һ�������starting tabula rasa�� ��һ�Ű�ֽ��ʼ����Zero��ѵ�����̣�����һ��Ӥ���ɳ�����Ȥ������
����������Сʱ����ͬ����ʯ�ӡ��ڶ�ʮСʱ���а����ۡ���70Сʱ�����Ӿ��洦�����磬���Ƕ�����֡�
������AlphaGoѧ��Ķ�ʽ��������Ȥ��A����AlphaGo��ѵ��������ѧ������ඨʽ��B��������ѵ���IJ�ͬ�Σ�AlphaGo��ϲ���Ķ�ʽ��
����B�е�һ������������1��1����Ȼ�����ȣ���ʱ����ǵ�10��Сʱ��B�еڶ���������λ�������⿿�����������ˣ��װ�ճ�ı仯���˱仯��������α����У���2�Ծ�㤣�ֱ�ۿ�Ҳ�ǰ����Կ�����Ȼ����40Сʱ�Ժ���ʽ��������̭������ͼ����
�����䣬��������ǧ����ʼ������ ����20Сʱ�Ժ�˱仯����Ƶ����������һ�ȴﵽ3%���˺������䣬�����ȶ���0.5%��������������ϲ���Ķ�ʽ֮һ��Ҳ�Ƕ�ʽ���ϱؽ��ܵ�һ�������͡��ڵذ��ƣ�����������
������Ϊ�Աȣ�����������һ�����£�
��������ʮСʱ��5�ɵ�Ƶ�ʴ�������70Сʱ���˱�Ƶ�ʴ�0.2%�������յ���ս�����������˱��Ƶ���ƺ������˺�5�⣨�д���֤����������˼��AlphaGo�Դ˶�ʽ����ʶ���̺�������Щ���ơ�������������5�ⶼ�ǵ������ı��仯��ֱ�����ʮ�����ң���5�ɲſ�ʼ���Ƶ������������Master��Ӱ�죬�������ֿ�ʼƵ�������������ҰѺ�5����Ϊ���仯����ͼ�ĺ���ֻ�Ǵ˶�ʽ��һ�䣬��Zero��ս���л�������һЩС�ĸĶ���
������һ������ʽ��������˼��
����1-5��������6��˼���룡��������ڿ��ֽ�����·�¡���10���Ժ�����Ҫ���ϣ������ǡ��ֲ���δ���ͣ���ʧ��������ϧ�˱�꼻�һ�֣���֪AlphaGo�Ƿ����˾ֲ����õ��ֶΡ�
��������һ����ȫ��Zero������
����37-41������������������һ��״̬������һ������ż��Ҳ����˱��ݣ��������AlphaGoֻ������������
������130�� ����ͬ����ˮ��©������ֻ����Aλ�ӡ�����Bλ�ԣ���O17���ɳ��塣��������Ժ�T17������ζ������
����Zero��Elo�ȼ�����5000�֣��˼������֡��������һ����Ի���ʤ�����ɼ���Χ���ϵ����о��롣Zero��Ϊ����Χ���˹����ܵĸ߷壬���в���Χ����յ㡣
�������ң�AlphaGo Zero�������¼������
����1��Zero�IJ��ԡ���ֵ�����Ƿ��������Ŀֵ����Ч������ֻ���7.5Ŀ����������δָ�����ٽ�һ����AlphaGo Zero��Ŀ�е������Ŀ�Ƕ��١�
����2��Zero�Ĺ��ӣ��ر���С���ӽΣ��Ƿ�᷸�����ص��ǣ�������Ϊ����ʧ��������̵���֡�
����3���Դ���ĿΪǰ�ᣬZero�����Ӧ����ģ���塣
����ϣ����������Reddit�ϵõ����
������ǧ���Χ�壬AlphaGoֻ�������߹������ԡ������ɡ���ʷ���������ģ���
������Գ��Ҿ��ֻ����ʯͷĥ����С��ʱ�ڡ�ͭ��¯�з����棬Ϊ�ʺ�ʱ�µã�������ǧ���ȡ������ѷ꿪��Ц���Ͻ����˴��乭�¡������ˣ���ԭѪ��
����һƪ����ͷ��ѩ�����ǵð߰ߵ�㣬���г¼������������ʥ�£�ƭ�����Ĺ��͡��ж��ٷ����������ׯ����������������ӻ��ᡣ��δ���������ס�